Movement and Containment in Texts and Hypertexts
This is just a sample. To put it in context, visit Hypertextual Ultrastructures' home page for an abstract, the full Table of Contents, and a link to
the full text of my dissertation.
- Boundaries, Membranes, Bindings
- Texts Wrapped in Claims
- Texts Inconsistent with Claims: Error
- Types of Error
- Types of Containment Error
- Claims of Internal Unreliability: This Made Sense to a Computer
- Claims of Impermanence and Limitation
- Claims of Loss: This May Not Be the Best Copy
- Claims of Passivity: “Powered by”
- Reliable Texts, Valid Software, Contextual Errors
- Managing Errors in Hypertexts: Proofreaders, Testers, Engineers, Editors

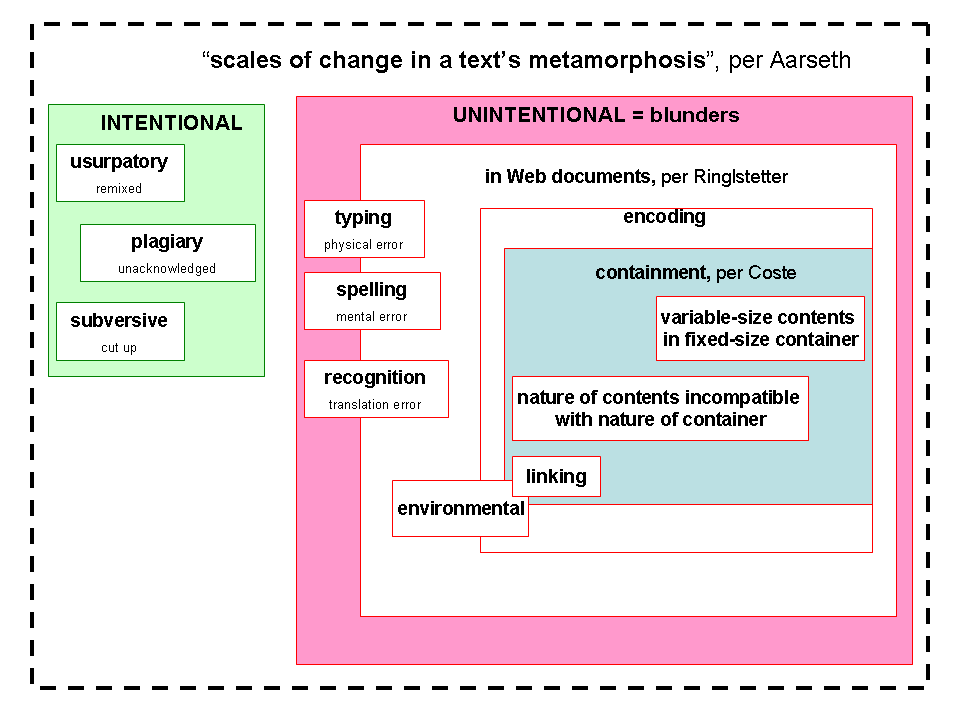
Types of Error
Textual studies has long used the observation and tracking of errors as a method of studying textual evolution and placing multiple copies of the "same" text in the proper relation to each other. If, as we study hypertexts, we are to continue gathering useful clues from errors, then we must also continue studying the nature of the errors themselves: What causes an error to occur? How can we detect an error? How is a text damaged by an error? How is the damage transmitted to its descendents?
Here, I propose a new class of errors particularly relevant to hypertextual studies: containment errors, in which the text's contents, although correct and complete, appear to be incorrect or incomplete due to incompability between the contents and their container.
As with some of my other observations about differences between texts and hypertexts, I think the key idea here is that hypertexts have a sub-surface nature. Studying hypertextual errors requires studying both the surface-level presentation and the sub-surface construction that introduces errors into that presentation.
Types of Containment Error
Here is a demonstration of containment errors that can easily be generated by the reader of a hypertext. In this example, navigation buttons are labeled with text that is perfectly correct but not necessarily readable, depending upon the reader's choice of browser settings. While intending to increase visibility (making the text larger), the reader can unintentionally decrease readability (making the text unusable).
 |
 |
 |
 |
 |
 |
| One “View—Text Size—Decrease” below the default browser setting allows all text to be read within its proper containers. | The default browser setting leaves some text truncated and other text overstruck and illegible. | One “View—Text Size—Increase” above the default setting forces some text out of its containers. | With text size increased two steps above the default setting, “Products & Services” has become entangled with “Strategic Planning” and “How To.” | Increased three steps, much of the text is overstruck. | At six steps above the default setting, the text is no longer readable as navigation links. |
I collected these screenshots of navigation buttons in 2007 from the US Patent and Trademark Office (USPTO) site at http://www.uspto.gov/. The buttons were unchanged at the site through the publication of my dissertation in 2009; I'm pretty sure they were unchanged as recently as 2011, although I can't prove it since I didn't capture any new samples. In mid-2012, the USPTO's site has been redesigned, but the phenomenon of navigational contents not fitting into navigational containers is easy to find elsewhere.
Because change, in container design as well as textual contents, is always possible, studying hypertexts means maintaining personal copies of them. When I study printed material, I might own a paper copy or might have borrowed it from a library or a friend; if I no longer have the paper in my possession, I can point you directly to it if I've described it well in my bibiliography. For hypertexts, though, even if I provide you with a hyperlink to exactly the page I was looking at, you may not see what I saw; I must support my observations with screenshots, and you must believe that I've done nothing to alter an image since I collected it. My favorite tool for collecting screenshots is SnagiIt, from TechSmith. As for proving that an image remains exactly as collected: in "Remediation: Creativity and Falsehood in Digital Images", I talk about some ways in which this can be done, but I don't have a favorite.